Discv5 Explainer Series: #1
Have you ever wondered how Ethereum nodes discover each other within the network? If so, this series is for you!
In this first blog post, we explain the Discv5 protocol, focusing on node identity and record management. Our goal is to explain the various components of the protocol in an accessible way, even if you're not familiar with cryptography or networking. Some prior knowledge of Ethereum basics may be helpful for following along.
We'll cover a wide range of topics, from encryption to topic advertisement and lookup, using examples to illustrate key concepts. By the end of this series, you'll have a solid understanding of how Discv5 works and why it's vital for the Ethereum ecosystem.
Intro to Discv5
One of the key components of Ethereum is its peer-to-peer communication system, which relies on a set of defined networking protocols. A networking protocol consists of rules that dictate how communication between two computers should happen. In the context of Ethereum, these protocols determine how nodes send or receive messages. For instance, one protocol specifies how nodes can discover each other on the network and exchange information about their capabilities and status. Another protocol defines how nodes can request and deliver blocks and transactions to each other. By following these protocols, nodes can communicate in a secure and compatible way. One of these protocols is Discv5, which stands for Discovery Protocol V5.
What is Discv5?
To understand what Discv5 is and how it relates to Ethereum, we can think of Ethereum as two layers: execution and consensus. In both layers, there are a collection of networking protocols that work in parallel for processing incoming requests and sending responses. In the execution layer, there is Discv4 (the previous version of Discv5) and DevP2P (a stack of protocols). The consensus layer uses Discv5 and LibP2P (a stack of protocols).
Discv5 is one of these protocols that enables nodes to discover each other to form a peer-to-peer network. Nodes using Discv5 can act as both a provider and a consumer of data and can communicate directly with other nodes without intermediaries. This allows for decentralisation, which means that there is no central authority or server that controls the network or its resources.
It was originally designed for Ethereum, but it can be applied to any network that needs a mechanism for discovering peers (nodes) and for connecting with specific peers that provide certain services. In comparison to its previous version Discv4, Discv5 is the latest version which provides additional features such as encrypted communication using cryptography and allowing nodes to broadcast information about their services in a scalable way to the network.
To learn more about its technical details, we will explore how nodes identify and manage each other's records in the network.
Node Identity and Record Management
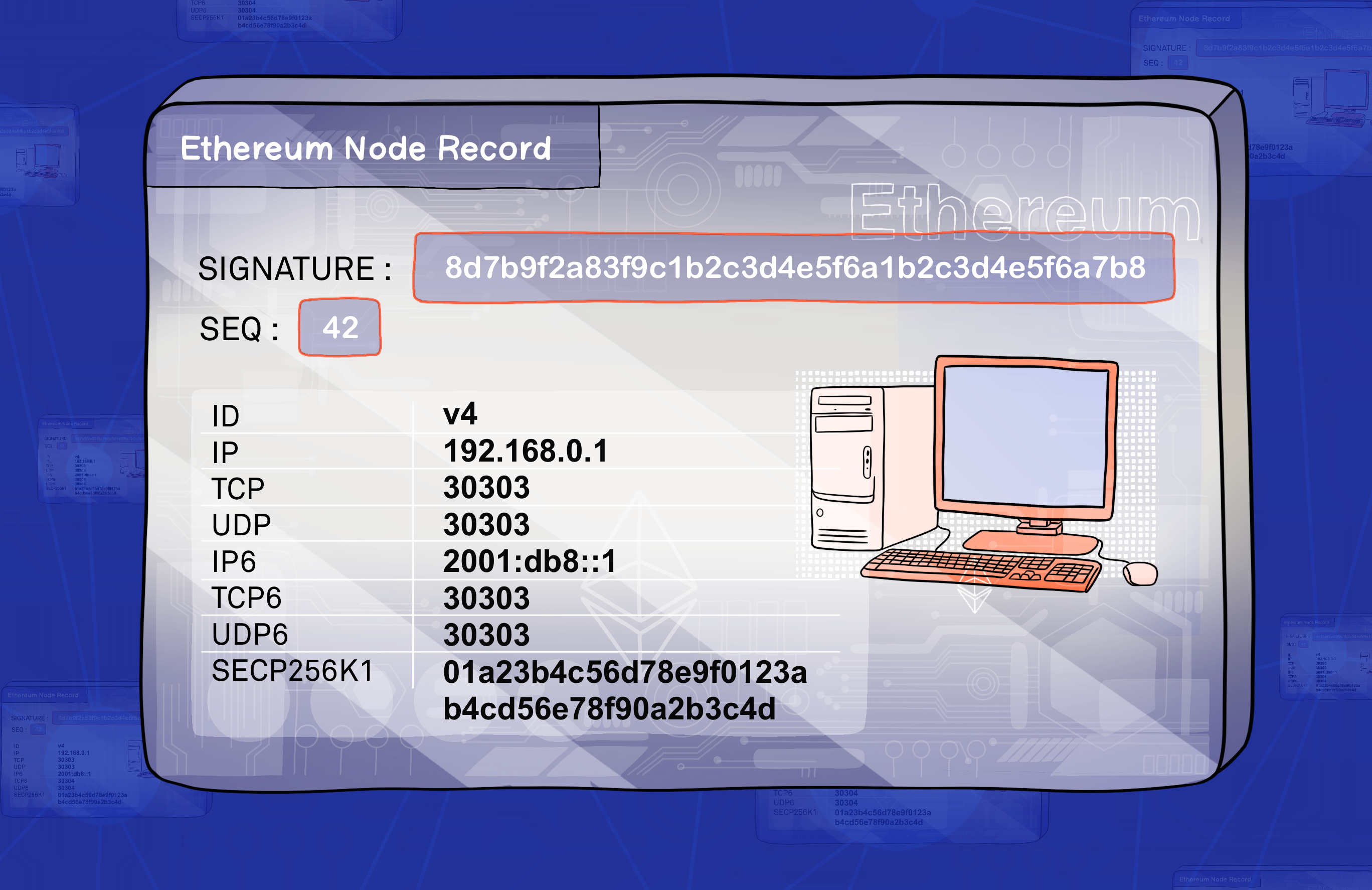
To participate in the Discv5 protocol, nodes need to create and maintain an identity that follows a standard format called Ethereum Node Record (ENR). This format is specified in EIP-778.
You can think of an ENR as a profile card that has some basic information about a node, like its IP address, port number, and what protocols it supports. We will use the term record to refer to an ENR for simplicity. Nodes can share their records with other nodes to make it easier to connect and communicate. The following part explains the contents of a record:
Signature- This is a way of proving that the record belongs to a certain node and that it has not been tampered with by anyone else. It is created by using a cryptographic method that involves applying a private key (known only by the node) to generate a unique code (called signature) from the record data. The signature can then be verified by anyone who has access to the public key (which is part of the record) using a matching cryptographic method .Seq- A number that indicates how fresh the record is. Whenever the node updates any of the fields in its record, it increases this number by one. This way, other nodes can tell which record is more recent and avoid using outdated information.Key/Value pairs- A data structure that stores various attributes of the node, such as its IP address, port number, and supported protocols. Each attribute has a key (a short name) and a value (the actual data). For example, the keyipmight have the value 192.168.0.1. The key/value pairs can be customised to suit different needs and preferences of the node.
The table below shows the common key/value pairs that are used by the Discv5, as defined in the EIP:
| Key | Value |
|---|---|
| id | This is a short label that tells other nodes what kind of identity scheme the node uses. For example, "v4" means that the node uses a version 4 identity scheme. The identity scheme defines how nodes create and verify their identities. |
| secp256k1 | This is a long string of letters and numbers that represents the node's public key. The public key is part of a cryptographic system that allows nodes to prove their identity and sign messages. The public key can be shared with anyone who wants to communicate with the node. |
| ip | This is a series of numbers separated by dots that identifies the node's location on the internet. For example, "192.168.0.1" is an IP address. The IP address helps other nodes find and connect to the node over the internet. |
| tcp | This is a number between 0 and 65535 that specifies the TCP port used by the node. TCP stands for Transmission Control Protocol, which is a method of sending data over the internet reliably and in order. The TCP port helps other nodes establish a TCP connection with the node for data exchange. |
| udp | This is a number between 0 and 65535 that specifies the UDP port used by the node. UDP stands for User Datagram Protocol, which is another method of sending data over the internet quickly and without waiting for confirmation. The UDP port helps other nodes send UDP packets to the node for data exchange. |
| ip6 | This is an alternative way of writing an IP address using hexadecimal digits and colons instead of decimal digits and dots. For example, "2001:db8::1" is an IP6 address. IP6 stands for Internet Protocol version 6, which is a newer version of IP that can support more devices on the internet than IP version 4. |
| tcp6 | This is similar to tcp, but it works with IP6 addresses instead of IP4 addresses. |
| udp6 | This is similar to udp, but it works with IP6 addresses instead of IP4 addresses. |
While id key is mandatory, all other keys are optional, meaning they may or may not be there in a node’s record. As mentioned earlier, this record format is flexible by allowing adding custom key-value pairs specific to network or application. This lets nodes in the network include more information as needed.
You might wonder about the purpose of different keys, such as ip6, tcp6, and udp6. In some networks, multiple devices may share the same public IP address, which can make it difficult to connect to specific devices. This problem is solved by including both IPv4 and IPv6 addresses in the record. This ensures that nodes can be reached from both types of networks, making it easier for devices to connect to each other.
Kademlia-Inspired Routing Table
In this section, we will learn how nodes keep track of other nodes in the network. Each node maintains a data structure called a routing table. The design of this table is inspired by the Kademlia DHT (Distributed Hash Table) that is commonly used by distributed file sharing or data storage systems. The Kademlia DHT stores key-value pairs, where the key is the hash of the content and the value is the actual content (e.g. file). The keys in the DHT are organised based on the closeness of node IDs. We will discuss this more in a moment, however, it is important to mention how the routing table in Discv5 differs from Kademlia DHT and why it is used in the first place.
In the Discv5 protocol, nodes neither store files nor provide storage to other nodes. Instead, they maintain a routing table with records (ENRs) that are relayed according to the requested distances from other nodes. This process enables the discovery of new nodes through a scalable data structure that grows with the number of nodes. No matter the size of the network, any node can be found using a lookup mechanism. Now we can look at the routing table and what is involved in maintaining it.
A routing table is like a phone book that stores the records of other nodes. If we recall from the previous section, each record has an ID that uniquely identifies the node. Nodes with similar IDs are considered neighbours because they are close to each other in the network's logical structure, not in terms of physical distance. To measure the closeness between two nodes, we use a mathematical operation called XOR to calculate a "distance" between their IDs. XOR stands for exclusive or, which is a logical operation that takes two inputs and returns true if only one of its inputs is true. If both inputs are false, the result is also false. We can use XOR to compare two node IDs and determine their relative distance within the network's logical organisation. Let's see an example with two node IDs:
Node A = 10 Node B = 12
To calculate the XOR of these node IDs, we first write them in binary form (using only 0s and 1s). This means converting the values 10 and 12 to their binary equivalents:
Node A = 1 0 1 0 Node B = 1 1 0 0
Next, we compare each pair of bits (0 or 1) at the same position and write down a 0 if they are the same or a 1 if they are different:
1 0 1 0 1 1 0 0 --------- 0 1 1 0 ---------
So, the XOR distance between Node A and Node B is 0110, which is 6 in decimal notation. A larger XOR distance indicates that more bits are different, while a smaller XOR distance signifies that the nodes are closer to each other. This is how the routing table stores and retrieves records of other nodes based on their proximity.
Record Management
Building upon the routing table concept, we now delve into the specifics of how nodes manage the information about other nodes within the network. The routing table is organized into multiple buckets, each containing up to 16 node records. Each node can have up to 256 buckets in its routing table, with each bucket corresponding to a different distance range from the node, as measured by the XOR of their public keys.
The buckets are ordered by increasing distance from the node, so the first bucket contains the closest neighbours and the last bucket contains the farthest ones. Within each bucket, the node records are sorted by their last seen time, with the most recently seen ones at the back and the least recently seen ones at the front. This organisation allows the node to keep track of which neighbours are active and which ones are stale.
When a node learns about a new neighbour through a message or a lookup, it attempts to add the neighbour's record to the appropriate bucket based on distance. However, if the bucket is already full, the node does not simply overwrite an existing record. Instead, it checks if the least recently seen record in that bucket is still alive by sending a PING message (these will be explained in the next blog post). If a response is received within a certain timeout period, the record is considered still valid and remains in place. If no response is received or an error message is obtained, the record is deemed invalid or unreachable and gets replaced with the new record.
The routing table is dynamic and constantly updated as nodes join or leave the network or change their attributes. To maintain an accurate view of its neighbours, a node periodically refreshes its buckets by performing lookups for random targets within each distance range. This process enables the node to discover new nodes that have joined or moved closer to its vicinity and remove old nodes that have left or moved farther away.
Continue Reading
In this blog, we've covered the basic concepts of Discv5, such as how nodes create and verify their identities, how they store and update information about other nodes using Ethereum Node Records and routing tables, and how they manage the records they share with the network. These concepts are essential for understanding the discovery and communication processes of Ethereum nodes.
In our next post, we will explore how nodes communicate with each other using encryption and discuss the types of messages they relay to one another. Here's the link to part two.
The Discv5 protocol is implemented in the software of nodes according to the developer specification. For those curious, the official specification resides in the Devp2p GitHub repository.
We'd love to hear your thoughts on this series or any questions you may have. Feel free to share your comments below or reach out to us on social media. If you're interested in contributing to our C# implementation of Discv5, visit our GitHub repository for more information.
Furthermore, if you're interested in learning more about Ethereum or blockchain technology, here are some resources you might find helpful:


